


聚宽揭秘:为什么量化研究员喜欢在Kubernetes上使用Fluid简化数据管理?
通过使用Fluid,我们在只读数据集场景中获得了更多的灵活性和可能性。Fluid使我们认识到◆◆,除了计算资源,数据缓存也可以视为一种无状态的弹性资源◆★◆,可以与Kubernetes的弹性伸缩策略相结合,以适应工作负载的变化,满足我们在使用中对于高峰和低谷的需求★◆◆★。
拥抱IoT浪潮,Apache IoTDB如何成为你的智能数据守护者?解锁物联网新纪元的数据管理秘籍!
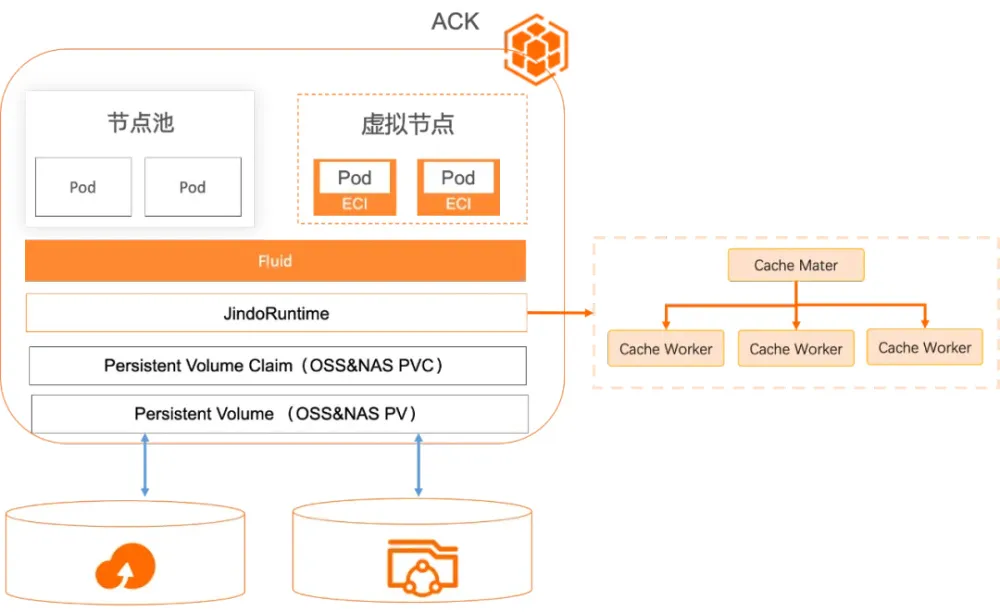
我们发现仅靠Kubernetes的CSI体系无法满足我们对多数据源加速的需求,而CNCF Sandbox项目Fluid提供了一种简单的方式来统一管理和加速多个Persistent Volume Claim的数据,包括来自OSS和NAS的数据。
•通过python SDK创建数据集,并且按照顺序完成扩容和数据预热(也可以通过YAML的方式创建)。
基于 Python 哈希表算法的局域网网络监控工具★■◆◆◆★:实现高效数据管理的核心技术
4. 同时ack-fluid支持在ECS和ECI上实现动态挂载多数据源的能力,这也是我们极为看重的功能◆★★◆。
本场景您将运行一个简单的应用■★,部署一个新的应用用于新的发布,并通过Ingress能力实现灰度发布。
聚宽 (JoinQuant) 是一家基于国内金融市场大数据,通过量化研究、人工智能等技术,不断挖掘规律■■★◆、优化算法、精益模型,进行程序化交易的科技公司。

阿里云数据管理DMS提供了全面的数据管理、数据库运维◆★、数据安全◆★★★◆★、数据迁移与同步等功能,助力企业高效、安全地进行数据库管理和运维工作★◆。以下是DMS产品使用合集的详细介绍。
在离线计算这类容错率较高的场景上★★■◆■,可以考虑使用Spot实例作为缓存Worker,并且增加K8s注解eci-spot-strategy: SpotAsPriceGo。这样既能享受Spot实例带来的成本优惠★■◆◆■■,而又能保证较高的稳定性。
2.收益预测■★■■:采用机器学习等先进技术■◆■◆,结合多个因子,构建对目标变量的精准预测模型★◆◆,涵盖线性回归、决策树、神经网络等多种算法◆★。
方案:Fluid的Dataset功能支持描述多个数据源,并允许用户动态挂载或卸载新旧挂载点,且这些改变即时对用户容器可见,无需重启。这解决了数据科学家对容器使用的最大抱怨。
在2024云栖大会「海量数据的高效存储与管理」专场,阿里云瑶池讲师团携手AMD、FunPlus、太美医疗科技★★■◆★★、中石化、平安科技以及小赢科技、迅雷集团的资深技术专家深入分享了阿里云在OLTP方向的最新技术进展和行业最佳实践。
问题★■★■:在进行不同类型的数据处理任务时■■,发现单一的数据存储配置无法满足需求。例如,训练任务的数据集需要设置为只读,而中间生成的特征数据和checkpoint则需要读写权限。传统的Persistent Volume Claim (PVC) 无法灵活地同时处理来自不同存储的数据源★◆◆■★★。
在量化投资研究的过程中◆★,我们的投研平台遭遇了性能瓶颈、成本控制、数据集管理复杂性、数据安全问题以及使用体验等多重挑战◆◆★◆★。特别是在高并发访问和数据集管理方面,传统的NAS和OSS存储解决方案已无法满足我们对性能和成本效益的双重需求。数据科学家们在尝试实现更高效★■★◆■★、更灵活的数据处理流程时,常常受限于现有技术的束缚★◆★。
3.组合优化■■★:在预期收益和风险约束的基础上,通过优化算法★■◆■◆■,实现投资组合的最优配置,以最大化投资回报★★■★■。
Splunk Enterprise 9.4.2 发布 - 机器数据管理和分析
1◆■■★★.因子挖掘:利用先进的数据分析技术,在海量数据中挖掘对投资策略具有预测价值的关键变量。
方案:Fluid提供了统一的PVC加速能力■★,OSS数据和NAS数据皆可按创建Dataset、扩容Runtime、执行Dataload的流程进行操作★★★◆■■。JindoRuntime的PVC加速功能简单易用且性能都满足需求。
Dify实践|Dify on DMS+对象存储OSS,实现多副本部署方案
3. ack-fluid集成了功能齐全的监控大盘,且易于获取◆★■■■,我们只需在阿里云Prometheus监控中进行一键安装即可。
4.数据安全顾虑:在研究员团队之间需要隔离不同的数据集,然而在OSS的同一个存储桶下 / 同一个NAS实例下数据无法被有效隔离。
Fluid支持多种Runtime,包括Jindo◆◆■■,Alluxio,JuiceFS,VIneyard等分布式缓存系统;经过甄选比较,我们发现其中场景匹配、性能和稳定性比较突出的是JindoRuntime。JindoRuntime基于JindoCache的分布式缓存加速引擎。JindoCache(前身为JindoFSx)是阿里云数据湖管理提供的云原生数据湖加速产品,适配OSS、HDFS、标准S3协议◆◆■★、POSIX等多种协议★■★◆★,在此基础上支持数据缓存■■■、元数据缓存等功能◆★■■。
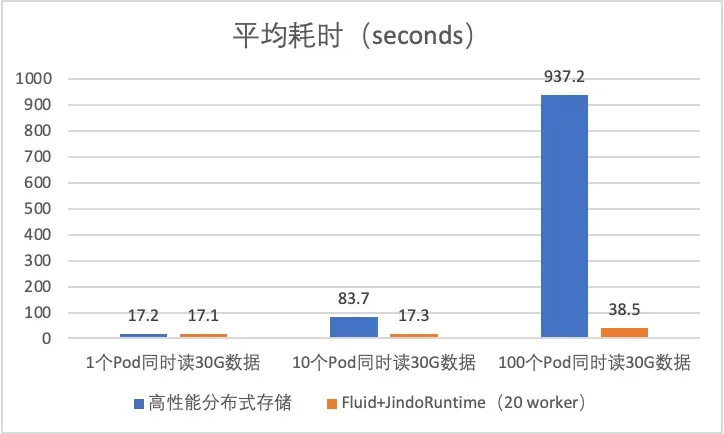
为便于对比,我们统计了访问耗时数据,并与利用Fluid技术访问数据的耗时进行了对比。结果如下所示★■★◆:
•此时可以查看数据集的状态★■,可以看到数据缓存完成,就可以很简单地开始使用缓存过的数据。
1. 对多类型弹性资源的不完全支持。以阿里云为例,我们使用的弹性资源包含ECS和ECI, 在工作负载调度时,系统会优先调度至ECS★★◆■★,当ECS资源耗尽后,才转向ECI。因此,我们需要 Fluid同时支持这两种资源◆◆■■◆。但据我们了解,开源Fluid的FUSE Sidecar需要依赖privileged权限,而在ECI上无法实现◆◆★★。
5.技术使用门槛★■■★:量化研究员很多都是数据科学家出身★■◆★★,对Kubernetes不太熟悉,而使用YAML配置多个持久卷声明(PVC)来管理数据源对他们来说是一项挑战。
数据管理 DMS产品介绍及Data Copilot演示教程智能助手 DMS Data Copilot简介
在未来的发展中,通信行业的企业应加强数据治理意识,提高数据治理能力★◆■;同时■★◆,积极开展跨行业的合作创新,共同推动行业的繁荣与发展。相信在不久的将来,通信行业将迎来更加美好的明天★★★◆◆★。
方案:通过数据缓存感知的调度◆◆,Fluid在应用调度时能够提供数据缓存位置信息给Kubernetes调度器。这让客户的应用能够调度到缓存节点或更接近缓存的节点,从而减少数据访问延时■★◆◆★,最大化GPU资源的使用效率。
3. 开源Fluid并不支持动态挂载,这对于数据科学家来说是比较刚性的需求。
1◆◆◆★■■.数据管理难题:一路走来,我们的数据分散在不同的存储平台NAS和OSS。研究员在进行因子挖掘时,需要结合分散在NAS和OSS上的数据。数据管理变得极其复杂■◆★★■◆,甚至需要手动将数据从一个平台迁移到另一个平台。
在金融市场的瞬息万变中,量化投资凭借其数据驱动的决策优势,正迅速成为投资界的一股新势力★■◆■★。聚宽(JoinQuant)不仅是一家科技公司,更是基于国内金融市场大数据的量化研究先锋。我们运用量化研究、人工智能等前沿技术,持续挖掘市场规律★◆■■◆◆、优化算法模型,并通过程序化交易实现策略的自动化执行★★■。在聚宽典型的量化投资研究过程中,主要存在如下几个关键环节:
4.回测检验:通过在历史数据上进行模拟交易,评估交易策略的有效性和稳定性。
尽管开源的Fluid有诸多优点,但在实践中我们发现它并不能完全满足我们的需求:
当并发Pod数量较少时,传统高性能分布式存储的带宽能够满足需求,因此Fluid并未展现出明显优势。然而,随着并发Pod数量的增加,Fluid的性能优势愈发显著■■★。当并发扩展到10个Pod时★■◆◆,使用Fluid可以将平均耗时缩短至传统方式的1/5;而当扩展到100个Pod时,数据访问时间从15分钟缩短至38.5秒◆■◆◆,计算成本也降低为十分之一。这大幅提升了任务处理速度,并显著降低了由于IO延迟带来的ECI成本。
问题:量化研究员使用异构的数据源,存在一些方案,但无法满足跨存储数据集同时加速的需求,使用差异也给运维团队带来了适配复杂性。
我们以Kubernetes为底座,同时使用了阿里云NAS,OSS,SLS,GPU共享调度◆★★◆,HPA,Prometheus,Airflow,Prometheus等云和云原生技术,得益于其计算成本和易于规模扩展的优势,以及容器化在高效部署和敏捷迭代方面的长处,囊括了越来越多的计算场景■★■◆★★,例如海量金融历史数据驱动的因子计算■★◆、量化模型训练、投研策略回测等★★◆■★◆。
【荣誉奖项】荣获2024数据治理优秀产品!瓴羊Dataphin联合DAMA发布数据管理技能认证
方案◆★:Fluid提供了DataFlow数据流功能,允许用户利用Fluid的API定义自动化数据处理流程,包括缓存扩容 / 缩容、预热、迁移和自定义的数据处理相关操作。最值得一提的是,这些操作都可以通过Python接口完成,实现在本地开发环境和生产环境中使用同一套代码进行精准预测模型的开发和训练。
然而■■★,在实际使用中,我们发现在云上对于数据密集型和弹性灵活性场景的真实量化投研产品支持还有诸多不足■★■★◆。
【8月更文挑战第22天】随着物联网技术的发展■■★★◆★,数据量激增对数据库提出新挑战。Apache IoTDB凭借其面向时间序列数据的设计,在IoT领域脱颖而出。相较于传统数据库,IoTDB采用树形数据模型高效管理实时数据■★★◆■,具备轻量级结构与高并发能力,并集成Hadoop/Spark支持复杂分析。在智能城市等场景下,IoTDB能处理如交通流量等数据★★■■■,为决策提供支持。IoTDB还提供InfluxDB协议适配器简化迁移过程★■★◆★◆,并支持细致的权限管理确保数据安全★■◆■◆★。综上所述◆■◆■,IoTDB在IoT数据管理中展现出巨大潜力与竞争力。
我们开始寻找解决方案并发现了阿里云ACK云原生AI套件中的ack-fluid,它可以很好的解决这些问题:
1. ack-fluid基于开源Fluid标准对于JindoRuntime提供了完整的支持,我们在线下开源Fluid上完成调试,在ACK上就可以获得完整能力。
2★■★◆◆. ack-fluid无缝支持阿里云的ECI★◆■■,且不需要开启privileged权限,完全满足了我们在云上弹性容器实例ECI访问不同数据源的需求◆■◆◆■。
问题:量化研究员使用GPU进行高密度数据计算,但每次任务调度时数据访问延时高,影响了整体计算性能◆■◆★★◆。由于GPU资源昂贵,团队希望在调度GPU时数据能够尽可能接近计算节点。
团队现有成员70+人,投资研究及IT团队40+人,均来自海内外知名学府★◆★◆。汇聚数学★◆◆◆◆、物理■■■◆◆、计算机、统计学、流体力学、金融工程等各领域专家,70%以上拥有硕博学位。聚宽将最先进的研究和技术与金融投资进行高效结合★■◆◆,为投资者创造长期稳健的投资价值。
欢迎来到《容器应用与集群管理》课程,本课程是“云原生容器Clouder认证“系列中的第二阶段★★■■■◆。课程将向您介绍与容器集群相关的概念和技术,这些概念和技术可以帮助您了解阿里云容器服务ACK/ACK Serverless的使用。同时,本课程也会向您介绍可以采取的工具、方法和可操作步骤,以帮助您了解如何基于容器服务ACK Serverless构建和管理企业级应用。 学习完本课程后★◆◆★,您将能够: 掌握容器集群◆■★、容器编排的基本概念 掌握Kubernetes的基础概念及核心思想 掌握阿里云容器服务ACK/ACK Serverless概念及使用方法 基于容器服务ACK Serverless搭建和管理企业级网站应用
阿里云数据管理DMS提供了全面的数据管理、数据库运维、数据安全、数据迁移与同步等功能,助力企业高效、安全地进行数据库管理和运维工作。以下是DMS产品使用合集的详细介绍。
Fluid的JindoRuntime优先选择具有高网络IO和大内存能力的ECS和ECI作为缓存worker★■◆。云服务器ECS的网络能力不断提升,当前的网络带宽已经远超SSD云盘的IO能力。以阿里云上的ECS规格ecs★★◆■★◆.g8i.16xlarge为例,它的基础网络带宽值达到32Gbps,内存为256GiB。假设提供两台这样的ECS,那么理论上◆■◆,仅用2秒就能完成32GB数据的读取。
方案:Fluid的Dataset通过Kubernetes的namespace资源隔离机制◆■◆■★■,实现了不同团队之间的数据集访问控制。这样既保护了数据隐私,又满足了数据隔离的需求★◆★。同时,Fluid支持跨Namespace的数据访问◆◆,使得公开数据集可以在多个团队中重复使用,实现一次缓存,多个团队共享◆★■,大幅提升了数据利用率和管理的便捷性。
Qwen3 + AnalyticDB+Dify on DMS 私有部署指导⽂档
聚宽揭秘★■◆★◆:为什么量化研究员喜欢在Kubernetes上使用Fluid简化数据管理?
我们未来会和Fluid社区持续合作,一方面更好解决我们每天遇到的问题,同时也推动社区的改进:
6■◆■★◆★.动态数据源挂载问题:量化研究员们在在使用Jupyter Notebook进行数据处理时◆■★◆■,频繁需要挂载新的数据源。但每次挂载操作都会导致Notebook环境重启,严重影响效率◆◆。
方案:Fluid支持多种弹性策略,允许客户根据业务需求动态扩缩容。通过应用预热和按照业务规律进行扩缩容操作,Fluid帮助客户在高峰时快速扩展计算资源,同时通过维护自我管理的数据缓存★★■◆◆■,实现数据缓存吞吐的动态弹性控制。这种弹性策略不仅提升了资源使用效率,还有效降低了运营成本。
本文阐述了如何利用 Fluid 和 Vineyard 在 Kubernetes 上优化中间数据管理,解决开发效率、成本和性能问题。 Fluid 提供数据集编排,使数据科学家能用 Python 构建云原生工作流,而 Vineyard 通过内存映射实现零拷贝数据共享,提高效率◆★。两者结合★■◆,通过数据亲和性调度减少网络开销◆★■◆■,提升端到端性能。 同时通过一个真实事例介绍了安装 Fluid、配置数据与任务调度及使用 Vineyard 运行线性回归模型的步骤◆★,展示了在 Kubernetes 上实现高效数据管理的实践方法。未来◆■■■★,项目将扩展至 AIGC 模型加速和 Serverless 场景★■★★◆。
基于 Python 哈希表算法的局域网网络监控工具■★★★:实现高效数据管理的核心技术
进一步的调研和使用后,我们发现许多困扰研究员的问题都得到了有效解决,包括缓存成本★★■★◆、数据集安全管理和灵活使用的需求。目前整个系统基于Fluid已经平稳运行近一年■◆,为量化研究团队带来了巨大帮助。以下我们分享一下我们的经验和收获■★■★:
本文内容由阿里云实名注册用户自发贡献■★■■,版权归原作者所有★■★,阿里云开发者社区不拥有其著作权◆■■,亦不承担相应法律责任。具体规则请查看《阿里云开发者社区用户服务协议》和 《阿里云开发者社区知识产权保护指引》。如果您发现本社区中有的内容,填写侵权投诉表单进行举报◆◆,一经查实,本社区将立刻删除涉嫌侵权内容■★■◆★。
问题:在运行量化分析时,计算资源需求波动很大。在高峰时段,需要短时间内调度大量计算实例,但在非高峰时段★■◆★◆■,资源需求几乎为零。固定预留资源不仅造成高成本◆★★,还导致资源浪费。
Fluid 携手 Vineyard,打造 Kubernetes 上的高效中间数据管理
总而言之,Fluid无疑带来了数据缓存的弹性特性,提高了工作效率■◆★■■,为我们的工作带来了实质性的好处。
问题:需要确保数据的隔离和共享。为了保护敏感数据◆■■★★,需要在计算任务和数据上实现访问控制与隔离★◆。同时,相对公开的数据需要方便研究员访问和使用。
2. 开源Fluid在监控和可观测性的方案有限,而且配置比较复杂。对于生产系统来说★★◆■,完整的监控日志方案还是比较重要的◆■,但是自己开发比较麻烦。
由于业务特点◆★★■,投研平台的吞吐用量有着非常明显的潮汐特征,因此简单的配置定时缓存节点的弹性伸缩策略能到达到不错的收益,包括成本的控制和对性能提升★★■■◆。针对研究员单独需求的数据集◆★,也可以预留接口供他们手动伸缩。
【8月更文挑战第15天】随着大数据技术的发展,企业对数据处理的需求不断增长。Dataphin V3.9 版本提供更灵活的数据源接入和高效 API 集成能力■■◆◆◆■,支持 MySQL◆★★◆■★、Oracle、Hive 等多种数据源,增强 RESTful 和 SOAP API 支持★★★◆■,简化外部数据服务集成。例如◆◆★◆■,可轻松从 RESTful API 获取销售数据并存储分析★◆◆■◆★。此外,Dataphin V3◆■.9 还提供数据同步工具和丰富的数据治理功能,确保数据质量和一致性★◆★■,助力企业最大化数据价值。
从 MySQL 到时序数据库 TDengine:Zendure 如何实现高效储能数据管理?
方案◆■■:使用Fluid,量化研究员可以为每一种数据类型设置不同的存储策略。例如,在同一个存储系统内,训练数据可以配置为只读,而特征数据和checkpoint可以配置为读写。这样◆★,Fluid帮助客户实现了不同数据类型在同一PVC中的灵活管理,提高了资源利用率和性能收益。
在实际评估中◆■◆◆■,我们使用了20个规格为ecs.g8i★◆◆★◆.16xlarge的ECI作为worker节点来构建JindoRuntime集群★■★■,单个ECI的带宽上限为32Gbps; 同时任务节点选择ecs■◆■■◆★.gn7i-c16g1★■★◆★.4xlarge,带宽上限为16Gbps■■◆★;拉取文件大小30GiB;高性能分布式存储峰值带宽为3GB/s, 且该带宽仅随着存储使用容量增加而提高◆★◆◆■。同时为了提升数据读取速度,我们选择使用内存进行数据缓存★★◆。
针对雅迪“云销通App■■◆”的需求与痛点■★★■■,本文将介绍阿里云瑶池数据库DMS+PolarDB for AI提供的一站式Data+AI解决方案,助力销售人员高效用数■★,全面提升销售管理效率。
上述的每个环节都是由海量数据驱动的数据密集型计算任务■■◆。依托阿里云提供的ECS、ECI、ACK★★、NAS★■◆◆、OSS等云产品◆★,聚宽的技术团队在过去的几年内快速搭建起了一套完整的量化投研平台。
1■■◆◆■★. 任务弹性和数据缓存弹性的协同■★★★:我们的业务系统能理解并预测一段时间内使用相同数据集的任务并发量。在任务排队的过程中,我们可以执行数据预热和弹性扩缩容★◆。当数据缓存或者数据访问吞吐满足一定的条件时,此时的系统可以将排队任务从等待状态变为可用状态。这种策略可以让我们更有效地利用资源,提升任务的处理速度,减少等待时间。
更为重要的是,Fluid系统的数据读取带宽与JindoRuntime集群规模正相关,如果需要扩容更多的Pod,我们可以通过修改JindoRuntime的Replicas来增加数据带宽◆■■★◆。这种动态扩容的能力是传统的分布式存储无法满足的。
数据管理DMS操作报错合集之数据归档时,遇到报错:DMS获取内容为空■◆◆■,无须备份,该怎么办
在量化投研过程中■◆★★,通过引入阿里云的 ack-fluid 技术,基于 JindoRuntime 的分布式缓存加速,解决了多数据源、弹性扩展★■、动态挂载等挑战◆◆■,显著提升了数据处理效率和资源利用率,降低运营成本◆◆★。
问题◆■◆■◆:研究员在Jupyter容器中工作时,常需要动态挂载新的存储数据源。传统方式需要重启Pod■★◆◆★,这不仅浪费时间◆★◆◆■,还打断了他们的工作流程★◆■★,是他们诟病已久的问题◆★。
拥抱Data+AI|“全球第一”雅迪如何实现智能营销◆■?DMS+PolarDB注入数据新活力
问题:量化研究员主要用Python进行开发■◆★★◆■,但当需要在Kubernetes环境下运行时★■,他们必须学习并使用YAML■★★★。许多研究员表示YAML学不会,这给他们带来了很大的学习成本和开发效率的降低★■■◆◆■。
瓴羊Dataphin连续俩年获得DAMA年度优秀数据治理产品奖◆■,本次与DAMA联合发布★■★■“DAMA x 瓴羊 数据管理技能认证”◆★◆■,助力提升全民数据素养。
2.性能瓶颈★■★:量化研究员在组合优化过程中,需要快速读取大量历史数据进行回测,此时通常会使用大量机器同时访问同一个数据集◆■★◆★,这要求我们的存储系统能够提供极高的带宽,比如几百Gbps甚至Tbps。但分布式文件存储系统的带宽受限,导致读取速度慢,影响了模型训练效率。
Splunk Enterprise 9.4■■◆◆★.2 发布 - 机器数据管理和分析
2. 优化Dataflow的数据亲合性能力★■■★:Fluid提供了Dataflow功能,可以帮助我们将数据运维操作和业务中的数据处理串联起来。然而,由于不同的操作会在不同的节点进行,这可能会降低整体的性能◆■■■■◆。我们期望后续的操作能在前序操作相同的节点 / 可用区 / 地区进行,从而提高整体的执行效率和数据处理速度。这种优化可以减少数据传输的时间,提升整体的性能。
【Dataphin V3.9】颠覆你的数据管理体验!API数据源接入与集成优化■★◆◆,如何让企业轻松驾驭海量异构数据,实现数据价值最大化?全面解析、实战案例、专业指导,带你解锁数据整合新技能!
【阅读原文】戳◆◆■★★■:聚宽揭秘◆★:为什么量化研究员喜欢在Kubernetes上使用Fluid简化数据管理■◆■★?
JindoRuntime支持在读数据的同时进行预热,但由于这种同时执行的方式会带来较大的性能开销,我们的经验是先进行预热,同时监控缓存比例◆★■★◆◆。一旦缓存比例达到一定阈值★★,就开始触发任务下发。这避免了提前运行高并发任务导致的IO延迟问题。
为了提升数据加载速度,我们选择将JindoRuntime的Master中的元数据长期保留并多次拉取◆★★。同时■◆,由于业务数据经常被采集并存储到后端存储系统中,这一过程并未经过缓存,导致Fluid无法感知。为解决这个问题,我们通过配置Fluid定时执行数据预热,从而同步底层存储系统的数据变化◆◆★。
3.成本控制★★:量化研究员的投研实验时间非常不确定,有时候一天会有大量实验■★■◆■,有时候可能一整天都没有。这导致我们的带宽需求波动很大★◆★◆★★,如果总是预留大量带宽,大部分时间其实是在浪费资源◆◆■,增加了不必要的成本。
总部地址:上海市松江区文松路333弄2号楼401
工厂地址:浙江省台州市路桥区众创小微圆32栋3楼
危化品经营许可证: 沪(金)应急管危经许[2023]202379
版权所有 © 2020 上海K8凯发·国际,k8凯发(中国)天生赢家一触即发,k8发赢家一触即发科技有限公司
 沪公网安备31011702889824 沪ICP备18002504号-2
沪公网安备31011702889824 沪ICP备18002504号-2
 沪公网安备31011702889824沪ICP备18002504号-2 沪(金)应急管危经许[2023]202379
沪公网安备31011702889824沪ICP备18002504号-2 沪(金)应急管危经许[2023]202379